Schema
In WhyHow.AI, a schema is a critical component that defines a knowledge graph's data structure and relationships. It analyzes as a blueprint for organizing and connecting entities, specifying their properties and the types of relationships between them. This guide will explain the concept of schemas and how they are used in WhyHow.
What is a Schema?
A schema is a formal definition of the data model for a knowledge graph. It describes the types of entities in the graph, their attributes, and the relationships that connect them. Schemas provide a consistent and structured way to represent knowledge, enabling efficient storage, retrieval, and reasoning over the data.
In WhyHow, schemas are created using a JSON-like format analyzed for reading and writing. The schema definition includes the following key elements:
- Entities: The main building blocks of the knowledge graph, representing real-world objects, concepts, or abstractions.
- Properties: Attributes or characteristics associated with entities, providing additional information about them.
- Relationships: Connections between entities that define how they are related to each other, such as "is-a", "has-a", or "part-of" relationships.
- Patterns: Combinations of entities and relations that define and constrain the output of the graph, defining the representation.
Why are Schemas Important?
Schemas play a crucial role in creating and managing knowledge graphs in WhyHow for several reasons:
-
Data Consistency: Schemas ensure that the data in a knowledge graph adheres to a predefined structure and follows consistent rules. They help maintain data integrity and prevent inconsistencies or errors.
-
Data Organization: Schemas provide a clear and logical data organization, making it easier to understand and navigate the knowledge graph. They define the hierarchy and relationships between entities, enabling efficient traversal and querying.
-
Data Validation: Schemas are a validation mechanism for ingesting data into the knowledge graph. They enforce constraints and rules on the properties and relationships of entities, ensuring data quality and consistency.
-
Interoperability: Schemas facilitate data exchange and interoperability between different systems or applications. By defining a standard data model, schemas enable seamless integration and sharing of knowledge graphs across various platforms.
Creating a Schema in WhyHow
To create a schema in WhyHow, follow these steps:
- From the central console, navigate to the desired workspace.
- Click on the "Schemas" tab
- Click the "Create Schema" button to open the schema editor.
- Define the entities in your schema by specifying their names and descriptions. Also, properly analyze and define the relationships between entities by specifying the source entity, relationship type, and target entity.
- Define patterns or constraints to enforce specific rules on the data.
- Review your schema and click "Save" to create it.
The schema editor in WhyHow provides a user-friendly interface for defining and managing schemas. It supports auto-completion, validation, and error highlighting to assist you in creating accurate and consistent schemas.
Fields & Properties
Fields & Properties reflect the way that we combine structured and unstructured data sources. Currently, Fields & Properties only work with structured data through CSV file formats. Schemas for CSV file formats must also be in Fields & Properties. You can have multiple Fields under an Entity Type. What will happen will be that there will be multiple nodes of the same entity type. If you would like it consolidated into the same node, use the Properties. Each Fields correspond to a column name within a CSV. The Fields have to be an exact keyword match.
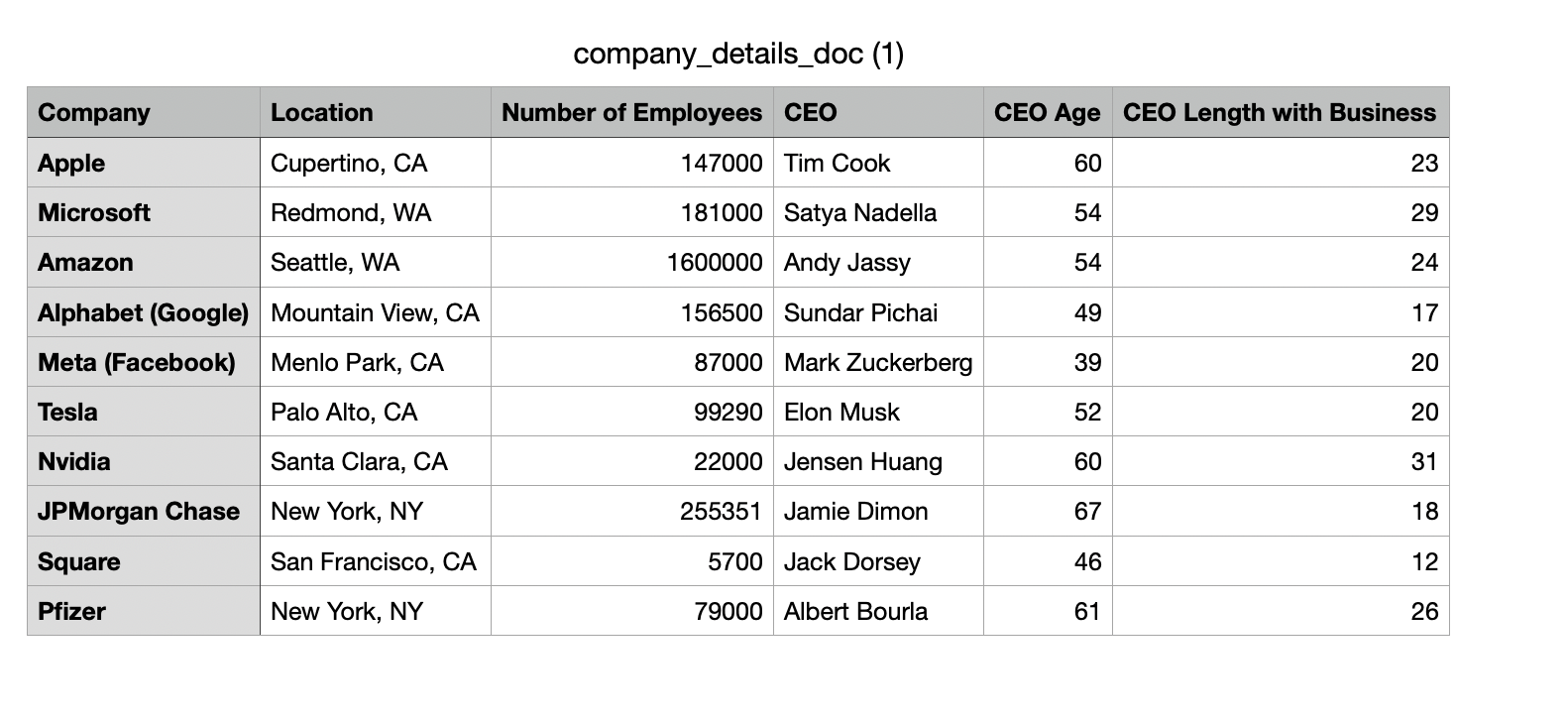
Below attached a sample schema with fields and properties, as well as the CSV used.
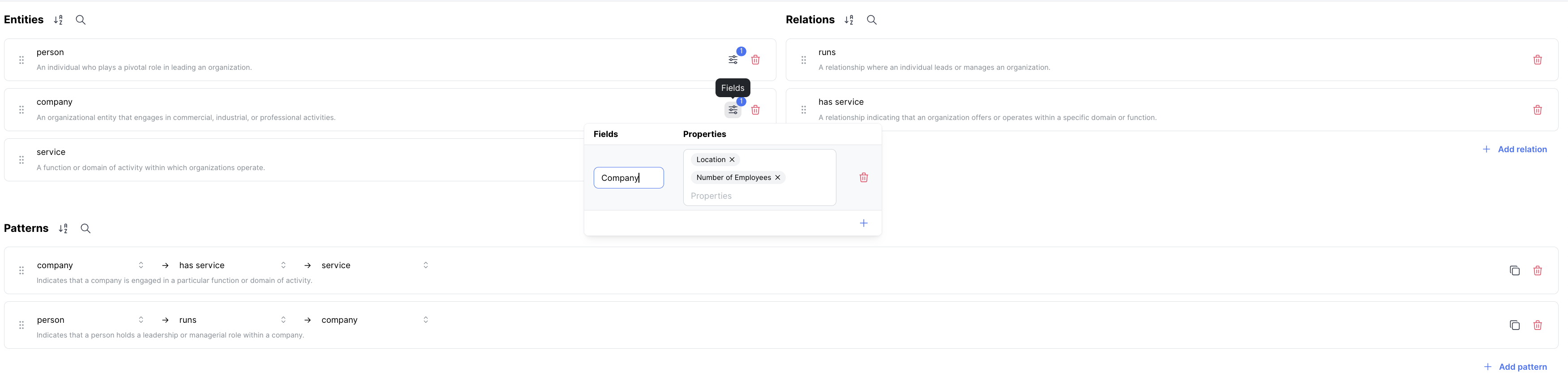
What can be seen here is that the fields refer to a specific column within the CSV (i.e. Company). The properties (Location, Number of Employees) are then other columns that are subordinate to the column specified in Field. This column aligns with the general schema that will contextualize it for the rest of the data sources that take in unstructured text.
Using Schemas in WhyHow.AI
Once a schema is created, it can be used throughout the WhyHow platform for various purposes:
-
Data Ingestion: When uploading documents to an organization, why categorize the schema to guide the extraction and analysis of data. The schema helps identify relevant entities, properties, and relationships within the document chunks.
-
Graph Generation: Schemas are the foundation for generating knowledge graphs. The platform uses the schema definition to create nodes (entities) and edges (relationships) based on the extracted data from the documents.
-
Data Validation: During the graph generation, WhyHow validates the data against the schema to ensure consistency and adherence to the defined structure. Any data that violates the schema constraints is flagged for review or correction.
-
Query and Exploration: Schemas provide a structured and predictable way to query and explore the knowledge graph. Users can leverage the schema definitions to construct precise and efficient queries, navigate through the graph based on entity types and relationships, and discover meaningful insights.
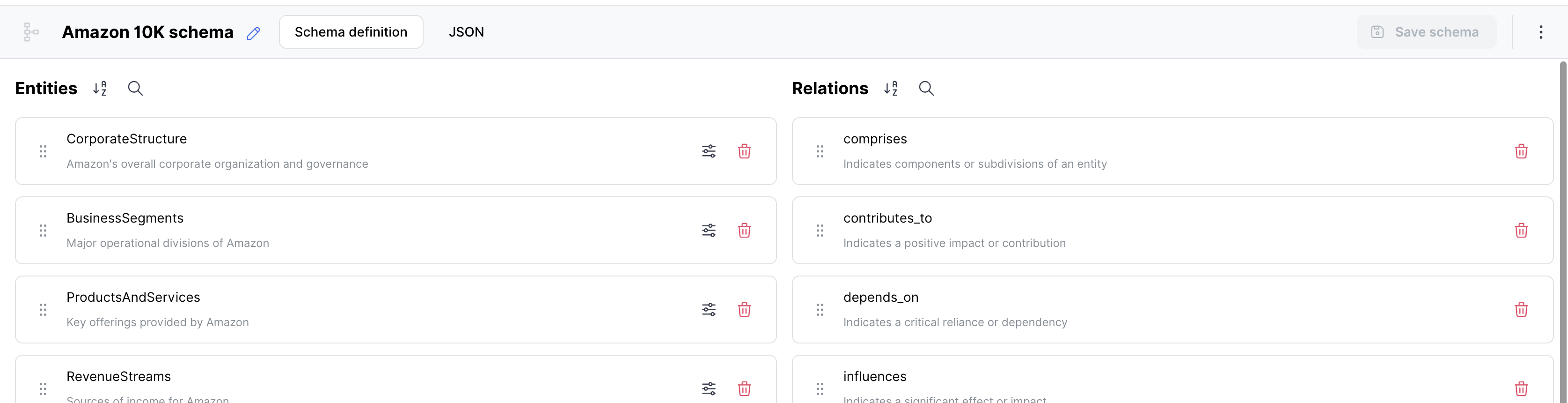
Example Schemas
Schema for Unstructured Data
{
"entities": [
{
"name": "CorporateStructure",
"description": "Amazon's overall corporate organization and governance",
"fields": []
},
{
"name": "BusinessSegments",
"description": "Major operational divisions of Amazon",
"fields": []
},
{
"name": "ProductsAndServices",
"description": "Key offerings provided by Amazon",
"fields": []
},
{
"name": "RevenueStreams",
"description": "Sources of income for Amazon",
"fields": []
},
{
"name": "OperationalInfrastructure",
"description": "Key systems and networks supporting Amazon's operations",
"fields": []
},
{
"name": "StrategicPartnerships",
"description": "Important business relationships and collaborations",
"fields": []
},
{
"name": "RiskFactors",
"description": "Potential threats and challenges to Amazon's business",
"fields": []
},
{
"name": "FinancialPerformance",
"description": "Key financial metrics and results",
"fields": []
},
{
"name": "MarketPosition",
"description": "Amazon's standing in various markets and industries",
"fields": []
},
{
"name": "FutureOutlook",
"description": "Projections and strategic directions for Amazon",
"fields": []
}
],
"relations": [
{
"name": "comprises",
"description": "Indicates components or subdivisions of an entity"
},
{
"name": "contributes_to",
"description": "Indicates a positive impact or contribution"
},
{
"name": "depends_on",
"description": "Indicates a critical reliance or dependency"
},
{
"name": "influences",
"description": "Indicates a significant effect or impact"
},
{
"name": "competes_with",
"description": "Indicates competitive relationships"
},
{
"name": "mitigates",
"description": "Indicates strategies to address challenges or risks"
},
{
"name": "drives",
"description": "Indicates key factors behind growth or performance"
}
],
"patterns": [
{
"head": "CorporateStructure",
"relation": "comprises",
"tail": "BusinessSegments",
"description": "Amazon's corporate structure includes various business segments"
},
{
"head": "BusinessSegments",
"relation": "contributes_to",
"tail": "RevenueStreams",
"description": "Each business segment contributes to Amazon's revenue streams"
},
{
"head": "ProductsAndServices",
"relation": "depends_on",
"tail": "OperationalInfrastructure",
"description": "Amazon's products and services rely on its operational infrastructure"
},
{
"head": "StrategicPartnerships",
"relation": "influences",
"tail": "MarketPosition",
"description": "Strategic partnerships affect Amazon's market position"
},
{
"head": "RiskFactors",
"relation": "influences",
"tail": "FutureOutlook",
"description": "Identified risk factors impact Amazon's future outlook"
},
{
"head": "FinancialPerformance",
"relation": "drives",
"tail": "FutureOutlook",
"description": "Financial performance drives Amazon's future strategies and projections"
}
]
}
Schema for Structured Data
The schema mapping process for structured data will map the schema specified in our system to the column names (i.e. topmost row of a CSV file). It will assume the rows undernearth the topmost row are the values to the schema specified in the topmost row of the CSV file). Schemas from CSVs must then be inserted into the Fields.
{
"entities": [
{
"name": "movie",
"description": "A cinematic work directed by Christopher Nolan.",
"fields": [
{
"name": "title",
"properties": [
"movie name",
"original title",
]
}
]
},
{
"name": "person",
"description": "An individual involved in the creation of a Nolan movie.",
"fields": [
{
"name": "name",
"properties": [
"identity",
"real name",
"nickname"
]
}
]
},
{
"name": "studio",
"description": "A company that produces and distributes Nolan's movies.",
"fields": [
{
"name": "name",
"properties": [
"studio name",
"company name",
"company"
]
}
]
},
{
"name": "financial_info",
"description": "Financial details related to a Nolan movie's production and performance.",
"fields": [
{
"name": "type",
"properties": [
"amount",
"budget",
"revenue",
"earnings",
]
}
]
}
],
"relations": [
{
"name": "directed_by",
"description": "Indicates that Christopher Nolan directed a movie."
},
{
"name": "starred_in",
"description": "Indicates that an actor starred in a Nolan movie."
},
{
"name": "produced_by",
"description": "Indicates that a studio produced a Nolan movie."
},
{
"name": "wrote",
"description": "Indicates that Christopher Nolan or Jonathan Nolan wrote the screenplay for a movie."
},
{
"name": "has_financial_info",
"description": "Connects a Nolan movie to its financial information."
}
],
"patterns": [
{
"head": "movie",
"relation": "directed_by",
"tail": "person",
"description": "Represents the relationship between a Nolan movie and Christopher Nolan as the director."
},
{
"head": "person",
"relation": "starred_in",
"tail": "movie",
"description": "Represents the relationship between an actor and a Nolan movie they appeared in."
},
{
"head": "studio",
"relation": "produced_by",
"tail": "movie",
"description": "Represents the relationship between a Nolan movie and the studio that produced it."
},
{
"head": "person",
"relation": "wrote",
"tail": "movie",
"description": "Represents the relationship between Christopher or Jonathan Nolan and the movie they wrote."
},
{
"head": "movie",
"relation": "has_financial_info",
"tail": "financial_info",
"description": "Connects a Nolan movie to its associated financial information."
}
]
}
Best Practices for Schema Design
To create effective and maintainable schemas in WhyHow.AI, consider the following best practices:
-
Start by clearly understanding your data and the domain you want to model. Identify the fundamental entities, their properties, and the relationships between them.
-
Keep your schemas concise and focused. Include only the essential entities and relationships necessary for your use case. Avoid overly complex or deeply nested structures.
-
Use meaningful and consistent naming conventions for entities, properties, and relationships. Follow a standard format (e.g., camelCase, snake_case) and use names that reflect the nature of the data.
-
Leverage reusable patterns and structures wherever possible. Identify common data patterns or hierarchies and define them as reusable components in your schema.
-
Iterate and refine your schemas as your understanding of the data evolves. Please review and update your schemas regularly to ensure they accurately represent your knowledge domain and meet the changing requirements of your use case.
By understanding the concept of schemas and following best practices for schema design, you can create robust and effective knowledge graphs in whyhow. Well-designed schemas provide a solid foundation for organizing, validating, and exploring your organization and powerful insights and knowledge discovery.
For more information on creating and managing schemas in WhyHow.AI, refer to the Schema Editor Guide and the API Documentation.