Quick Start Guide
Introduction
Welcome to the Quick Start Guide for WhyHow! This guide is designed to get you up and running with a basic graph to start exploring the core capabilities of the Knowledge Graph Studio. In this example, we'll build trples and construct a graph from an Amazon 10k document.
Prerequisites
Before you begin, set up your whyhow account and log into the platform (please refer to the Account Setup Guide). You should also install the WhyHow SDK.
The best way to crete a graph in WhyHow is through the SDK. Once you have installed the SDK, navigate to the Settings page of the Knowledge Graph Studio and copy your WhyHow API key so you can configure the SDK.
To keep your API key secure, set it as an environment variable. Open your terminal and run the following command, substituting the placeholder with your actual data:
export WHYHOW_API_KEY=<YOUR_WHYHOW_API_KEY>
Import and configure WhyHow SDK
With your environment variable set, you can now configure the WhyHow client in your Python script. The client will automatically read in your environment variable, or you can override this value by specifying it in the client constructor.
from whyhow import WhyHow
client = WhyHow(api_key="<your WhyHow API key>", base_url="https://api.whyhow.ai")
Create a workspace
We'll start by ceating a workspace. Workspaces are logical ways to separate your graphs. You may want to create separate workspaces for different teams, topics, domains, etc.
workspace = client.workspaces.create(name="10k")
Create triples
There are many different strategies and use cases for constructing triples. As you saw in the platform overview, we can manually construct triples using entities such as people and businesses. Many users construct triples from strutured data such as CSVs or JSONs. Other users like to leverage tools like the Lnagchain LLMGraphTransformer to extract triples from unstructured documents.
In order for knowledge graphs to effectively, and accurately support AI-enabled workflows, we believe triples need to be highly customized according to your use case. One-click, LLM-powered graph builders do not offer the granular control necessary to build graphs to effectively solve complex business problems, but they can be helpful for quickly exploring relationships in unstructured data. In this example, we'll extract triples from an Amazon 10k document using the Langchain LLMGraphTransformer, then conform those triples to the WhyHow triple format.
A triple consists of three components: a subject (or a head), a predicate (or a relationship), and an object (or a tail). It represents a statement or a fact about the relationship between two entities. Heads and tails are represented by Nodes, and nodes contain a name as well as a label which describes the type of entity it is. Relations define the nature of the connection between the subject and the object.
Nodes and relations can also contain properties which are metadata about the entity or their relationship.
Import tools
import itertools
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
from whyhow import Node, Relation, Triple
from dotenv import find_dotenv, load_dotenv
load_dotenv(find_dotenv())
Load and process 10k
llm = ChatOpenAI(model="gpt-4o-mini")
llm_transformer = LLMGraphTransformer(llm=llm)
# Downlaod the 2024 Amazon 10k from https://d18rn0p25nwr6d.cloudfront.net/CIK-0001018724/c7c14359-36fa-40c3-b3ca-5bf7f3fa0b96.pdf
filepath = "{YOUR FILEPATH}"
loader = PyPDFLoader(filepath)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=0)
split_docs = text_splitter.split_documents(docs)
Extract triples
allowed_entities = [
"CorporateStructure", "BusinessSegments", "ProductsAndServices", "RevenueStreams", "OperationalInfrastructure",
"StrategicPartnerships", "RiskFactors", "FinancialPerformance", "MarketPosition", "FutureOutlook"]
allowed_relations = [
"COMPRISES", "CONTRIBUTES_TO", "DEPENDS_ON", "INFLUENCES", "COMPETES_WITH", "MITIGATES", "DRIVES"
]
llm_transformer_props = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_entities,
allowed_relationships=allowed_relations
)
graph_documents_props = await llm_transformer_props.aconvert_to_graph_documents(split_docs)
triples = [chunk.relationships for chunk in graph_documents_props]
flat_triples = list(itertools.chain(*triples))
Convert to WhyHow triple format
def format_triple(triple):
"""
Format the LangChain triple into the desired structure.
Args:
triple: An object containing source, target, and type attributes.
Returns:
Triple: A Triple object with formatted head, relation, and tail.
"""
source = triple.source
target = triple.target
# Create and return a formatted Triple object
return Triple(
head=Node(name=source.id, label=source.type),
relation=Relation(name=triple.type),
tail=Node(name=target.id, label=target.type)
)
# Generate a list of formatted triples
formatted_triples = [format_triple(triple) for triple in flat_triples]
Construct the graph
Now, we can create a graph using the triples we constructed. A graph is simple a collection of triples, made up of nodes and relations.
graph = client.graphs.create_graph_from_triples(
name="Amazon 10k graph",
workspace_id=workspace.workspace_id,
triples=formatted_triples
)
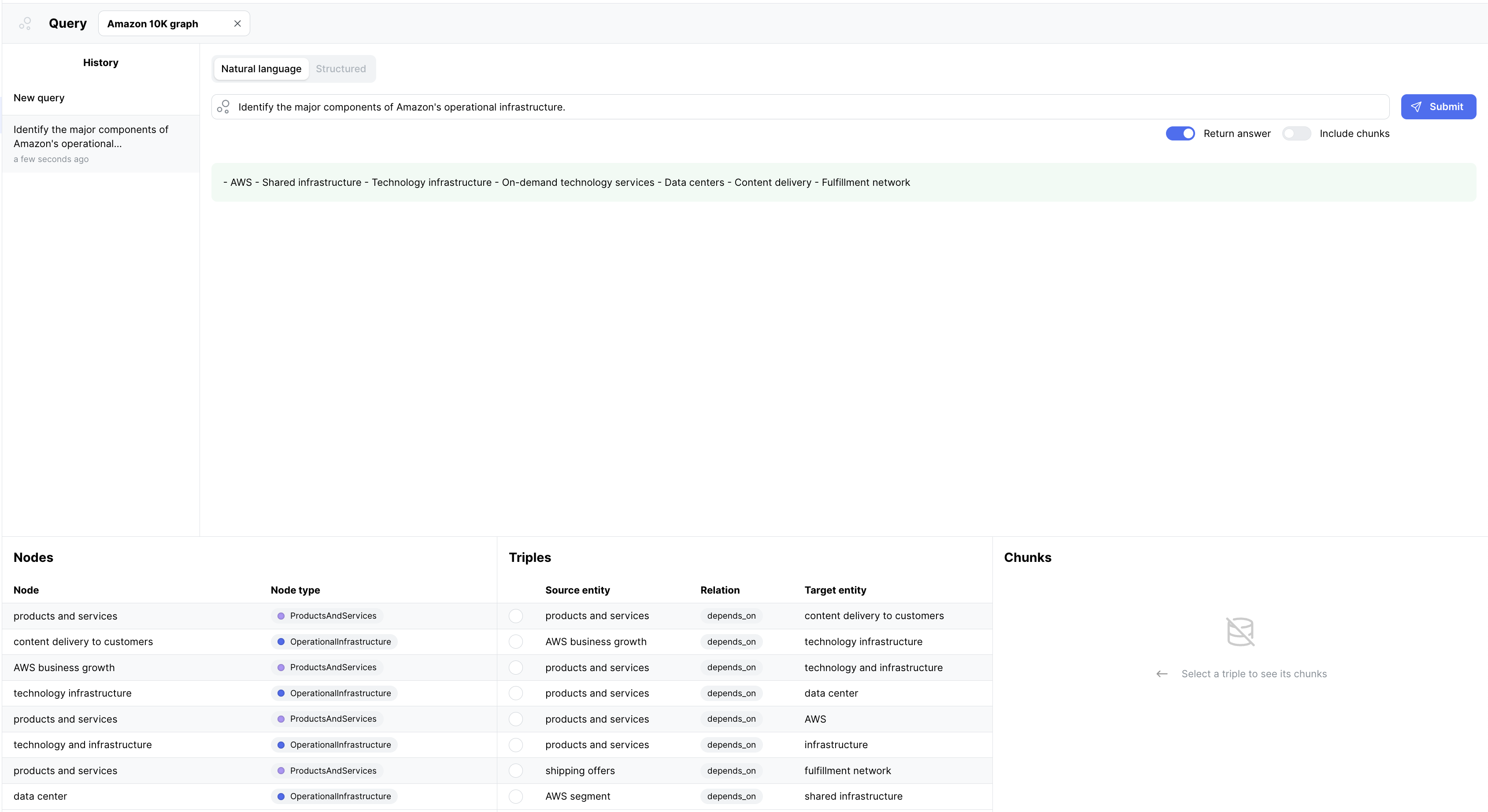
Exploring and Querying the Graph
Once the graph construction is complete, you can explore and query your graph in the Knowledge Graph Studio.
- Click on the "Graphs" tab in the project dashboard.
- Click on the generated graph to open the graph visualization interface.
- Use the interactive controls to zoom in/out, pan, and explore the graph structure.
- Click on nodes and edges to view their properties and relationships.
- Use the search and filtering options to find specific entities or patterns within the graph.
- Switch to the "Query" tab to execute custom queries using natural or structured query languages.
Experimenting Further
Congratulations on creating your first knowledge graph! Now that you have a basic understanding of the process try experimenting with different schemas, documents, and query techniques to uncover insights and relationships in your data.
Where to Go Next
To deepen your understanding of the whyhow platform and its capabilities, explore the following resources:
- Concept-specific Documentation: Learn more about the core concepts used in whyhow, such as graphs, triples, nodes, entities, workspaces, and chunks.
- User Interface Guide: Get familiar with the various components and features of the whyhow user interface.
- API Documentation: Discover how to interact with the whyhow platform programmatically using the API for more advanced use cases.